Chenyang Cao
 PhD student, University of Toronto
PhD student, University of Toronto
I am Chenyang Cao (pronounced as Chan-young Tsao in English), a first-year PhD student at the University of Toronto (UofT) advised by Prof. Nicholas Rhinehart. I used to study at Tsinghua University, advised by Prof. Xueqian Wang. I received my B.E. degree in mathematics from Fudan University, and I am lucky to work under the supervision of Prof. Zhenyun Qin and Prof. Hongming Shan. My research interests are reinforcement learning, robotics, continuous learning and motion planning. I am also interested in VLA and multimodal perception.

Education
-
University of Toronto
PhD in Aerospace Studies & Engineering and Robotics Sep. 2025 - Nov. 2029 (Expected)
-

Tsinghua University
MS in Electronic and Information Engineering Sep. 2022 - Jun. 2025
-

Fudan University
BS in Mathematics and Applied Mathematics Sep. 2018 - Jun. 2022
Honors & Awards
- First Class Scholarship of Tsinghua University SIGS 2024
- Second Class Scholarship of Tsinghua University SIGS 2023
- Meritorious Winner of Mathematical Contest in Modeling 2022
- Third Class Scholarship of Fudan University 2019-2022
Experience
-

Microsoft
Research Intern Oct. 2023 - Mar. 2024
News
Selected Publications (view all )
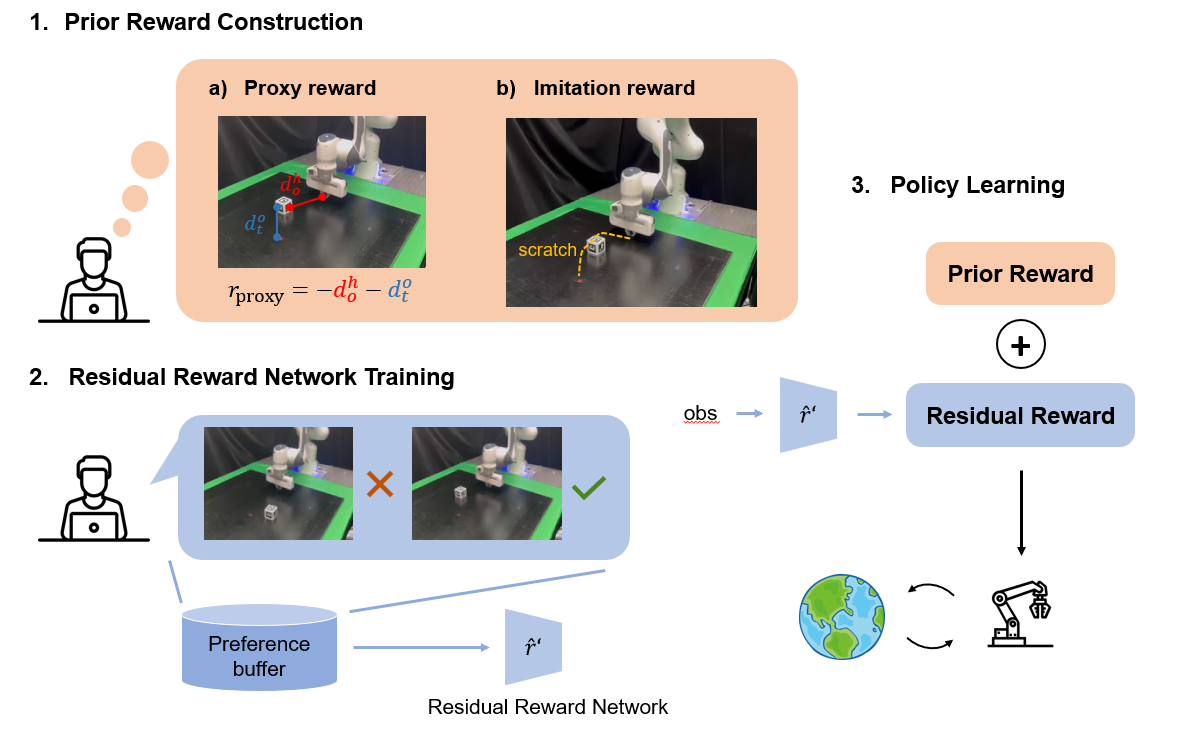
Residual Reward Models for Preference-based Reinforcement Learning
Chenyang Cao, Miguel Rogel-García, Mohamed Nabai, Xueqian Wang, Nicholas Rhinehart†(† corresponding author)
arXiv 2025 Conference
We propose a residual reward model for reward learning by effectively taking advantage of human prior knowledge.
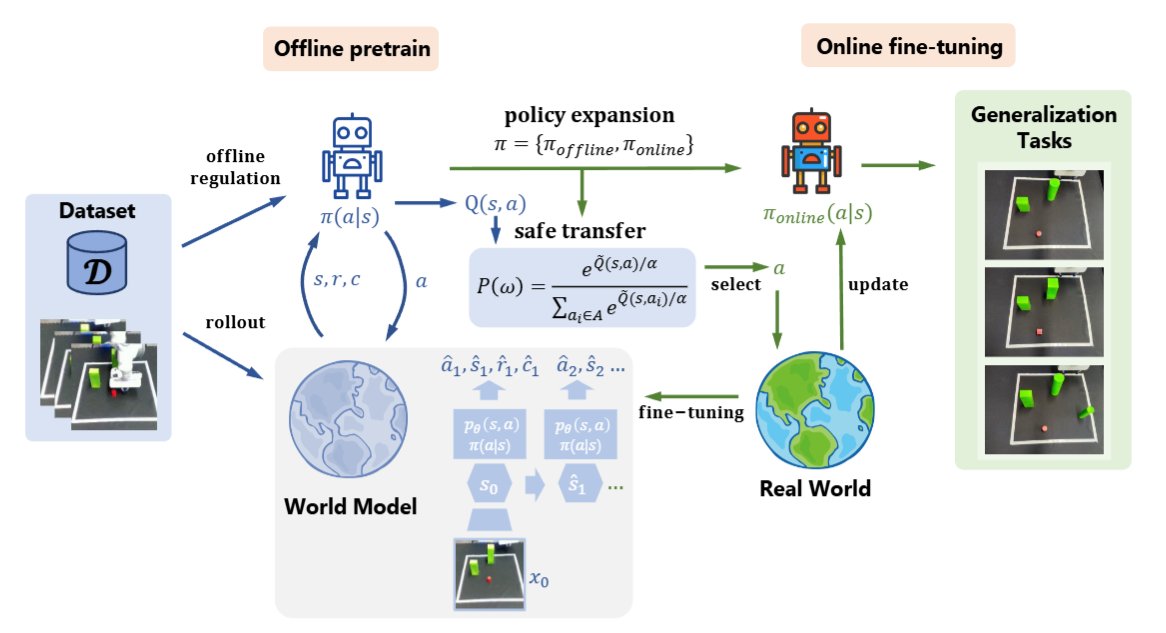
FOSP: Fine-tuning Offline Safe Policy through World Models
Chenyang Cao, Yuchen Xin, Silang Wu, Longxiang He, Zichen Yan, Junbo Tan, Xueqian Wang†(† corresponding author)
ICLR 2025 Conference
We propose a safe offline-to-online reinforcement learning algorithm by leveraging world models. It ensures the agent safely moves in the environment during online fine-tuning.
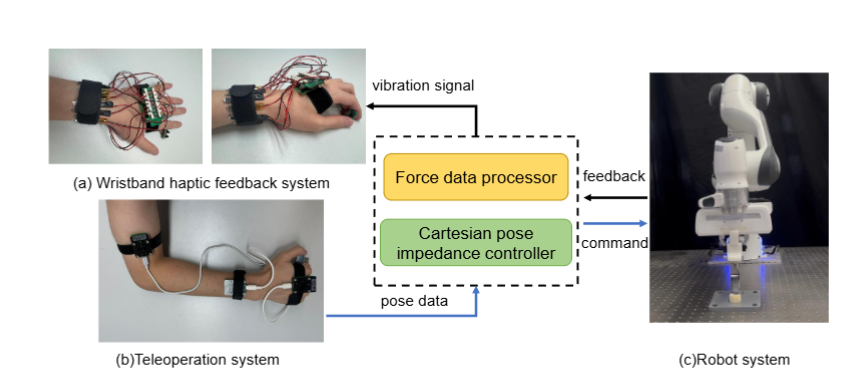
A Wristband Haptic Feedback System for Robotic Arm Teleoperation
Silang Wu, Huayue Liang, Chenyang Cao, Chongkun Xia, Xueqian Wang, Houde Liu†(† corresponding author)
ROBIO 2024 Conference
We make a wristband teleoperation system to provide haptic feedback from the end-effector.
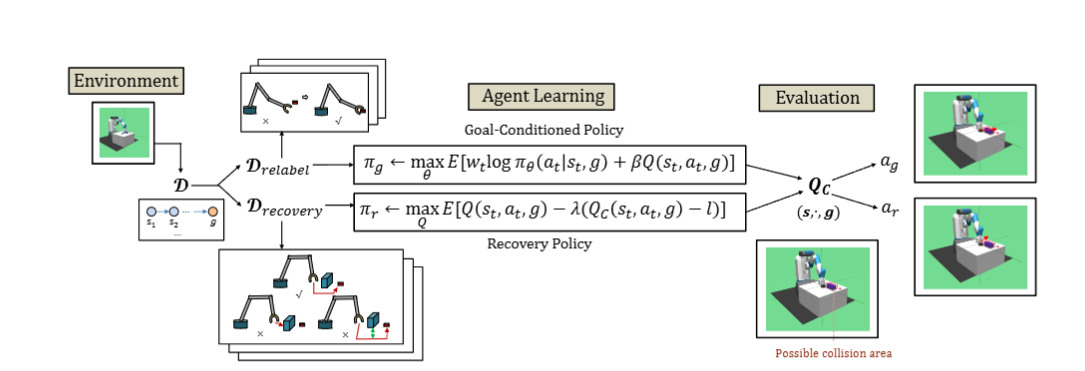
Offline Goal-Conditioned Reinforcement Learning for Safety-Critical Tasks with Recovery Policy
Chenyang Cao, Zichen Yan, Renhao Lu, Junbo Tan†, Xueqian Wang†(† corresponding author)
ICRA 2024 Conference
We propose an offline goal-conditioned reinforcement learning algorithm to solve the planning problem in constrained environments without interacting with them. The algorithm combines the advantages of efficient planning and safe obstacle avoidance, and effectively balances the optimization of both aspects.